Networking papers – Traffic Statistics
This section contains general papers about the statistics of network traffic, for example describing the distribution of round-trip times, triangle inequality violations and so on.
Improving content delivery using provider-aided distance information IMC 2010
The RTT distribution of TCP flows on the Internet… CAIDA tech report 2004.
On the predictability of large transfer TCP throughput SIGCOMM 2005
Improving content delivery using provider-aided distance information
Ingmar Poese, Benjamin Frank, Bernhard Ager, Georgios Smaragdakis and Anja Feldmann – T-Labs/TU Berlin
This paper looks at CDN networks and, in particular, suggests Provider-aided Distance Information System (PaDIS), which is a mechanism to rank client-host pairs based upon information such as RTT, bandwidth or number of hops. Headline figure, 70% of http traffic from a major european ISP can be accessed via multiple different locations. “Hyper giants” are defined as the large content providers such as google, yahoo and CDN providers which effectively build their own network and have content in multiple places. Quote: “more than half of the total traffic, including the dominant HTTP traffic, can be delivered in principle from multiple servers at diverse network locations based on obser- vations from passive packet-level monitoring” also “there is choice between at least two subnets over 40% of the time”.
Data: 1 day anonymised packet trace from large European ISP, 2 weeks of http data and 5 days of DNS data from same ISP. “HTTP alone contributes almost 60% of the overall traffic at our vantage point, BitTorrent and eDonkey contribute more than 10%.” Popularity of requests has a Zipfian distribution.
Figure 3 shows how a particular DNS resolver returns different results according to the type of content – in particular, a media server does load balancing using the DNS resolver. Two techniques can be used to map a DNS request to many IP addresses, either Multquery (one query returns several addresses) or Crossquery (repeated queries return different addresses).
A table is given which attempts to assess the proportion of http requests which could potentially be served within the ISPs own network depending on which DNS server the user uses (ISPs own, OpenDNS or GoogleDNS). The table has columns for “observed” (amount of content served which is within ISP network) and “potential” (amount which could be if DNS were more clever about addresses returned).
PaDIS allows optimisation based on delay (for small volume websites) or bandwidth (for bulk transfers) and it can be used as an ALTO server for localising P2P. PaDIS can reorder DNS responses according to these preferences for better use of network resources.
Experiments are performed from ten “vantage points” (presumably researchers and machines owned by them?). The PaDIS recommended server is compared with the CDN recommended one for speed of download at given times of day. PaDIS is shown to select servers with better download speeds.
Analysis is performed on One Click Hosts (OCH) and Video Streaming Providers as well. “Video streaming via HTTP is popular and accounts for more than 20% of the HTTP traffic.” “the most popular OCH… is responsi- ble for roughly 15% of all HTTP traffic” The conclusion is that OCH and VSP traffic could potentially be served from several servers.
The RTT distribution of TCP flows on the Internet and its impact on TCP based flow control
Srinivas Shakkottai, R. Srikant – University of Illinois and Nevil Brownlee, Andre Broido, kc claffy – Cooperative Association for Internet Data Analysis (CAIDA)
Downloadable from CAIDA http://www.caida.org/publications/papers/2004/tr-2004-02/
This paper looks at RTT and how they affect TCP flows. Because of limited data they look at how to derive RTTs from analysis of tcpdump data (unidirectional).
Methods of getting estimates of RTT are:
SYNSYN-ACKACK – the time stamp between SYN and ACK in triple handshake.
Flight method – look at packets with near identical inter-packet times. Calculate time between start of flights (attempt to ignore rate-limited flows).
Rate chage –
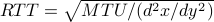 – estimate latter by change of
rate.
– estimate latter by change of
rate.
Three methods produce broadly comparable results.
Data:
OC48 Seattle – San Jose 2002 (1 hour) non anon
OC48 Seattle – San Jose 2003 (1 hour) non anon
Abeline (Kansas – Ohio) (1 hour)
Proposition 1: During TCP congestion avoidance, in interval ![[t_0,t_1]](eqs/2337264880867259360-130.png) average rate for interval (with no drops) reached at time
average rate for interval (with no drops) reached at time 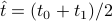 (middle of interval). The proposition is
misstated in paper (sign error) but correct in equation (3).
(middle of interval). The proposition is
misstated in paper (sign error) but correct in equation (3).
Methodology: To calculate rate they take the time taken for ten packets and the number of bits in those packets. RTT is calculated as a distribution over all IP pairs so distribution is for entire trace not disaggregated by IP pairs. Flights are identified as being related to bandwidth delay product and do not exist for all flows.
On the predictability of large transfer TCP throughput
Qi He, Constantine Dovrolis and Mostafa Ammar – Georgia Tech
This paper looks at ways of predicting the TCP throughput of a connection. The assumption is that some information is available about the connection. A comparison is made between “formula based” (FB) prediction, that is using round-trip time and loss versus time series analysis prediction (referred to here as history based (HB)), that is using previous measurements on the same connection. Both approaches require some measurements from the connection already.
The formula used is the standard from Padhye et al 2000 (a rather nice
model based approach to the problem) which takes RTT, loss and TCP parameters
such as max window, timeout and 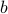 parameter (flights per window size increase).
They add corrections to this formula for connections which are observed lossless.
They also point out that queues at network edges increase RTT beyond its base
value. In addition ping based sampling of a network will underestimate the
loss suffered by a TCP connection as a TCP connection will ramp up to fill a pipe and
hence be part of the loss problem.
parameter (flights per window size increase).
They add corrections to this formula for connections which are observed lossless.
They also point out that queues at network edges increase RTT beyond its base
value. In addition ping based sampling of a network will underestimate the
loss suffered by a TCP connection as a TCP connection will ramp up to fill a pipe and
hence be part of the loss problem.
Measurement data is collected on 35 internet paths on RON testbed (nodes at US universities, + 2 in europe and 1 in korea). The 35 paths include 5 transatlantic , one korea to NY and the rest within US. Seven traces are used for each path – total 245 traces which collect available bw using tool called pathload – each trace is 150 measurements on path. Tool measures available bw then estiamtes RTT and loss. Then iperf is used to load path and RTT and loss rate measured during transfer. “A 50 second transfer… is enough to ensure that the flow spends a negligible fraction of its lifetime in the initial slow-start.” Measurements all from May 2004.
In general formula based prediction rarely underestimates bandwidth but sometimes overestimates – the overestimates tend to be larger in magnitude. In 40% of measurements the RTT increased significantly during a transfer and in “almost all” measurements the loss rate increased. “An increase in loss rate from 0.1% to 1% can cause a throughput overestimation by a factor of about 3.2”. Prediction errors remain signficant if the real RTT and loss during the connection are known. “More than half the prediction errors are still larger than a factor of two”.
History based prediction uses standard time series tools – n-step moving average (not real time-series analysis MA model), exponentially weighted moving average, Holt-Winters (non-seasonal). This is pretty much a starting point for time-series analysis and it seems clear that other tools could easily be tried – e.g. proper time series ARMA or even ARIMA model.
The history based methods perform reasonably at prediction even with just limited training data. Simple heuristics for outliers and level shifts improve errors. Some paths are more predictable than others.
The authors then investigate what makes a TCP flow predictable. They confirm that highly variable flows are harder to predict, flows where the initial measurement of available bw varies are harder to predict, flows competing with several other flows are harder to predict.
Conclusions: HB prediction good but requires initial data and varies with underlying path. FB prediction attractive because doesn't require intrusive measurements but can be inaccurate.
Home. For corrections or queries contact: Richard G. Clegg (richard@richardclegg.org)