Networking Papers – Network Economics
This section contains papers about the economics of network traffic.
Good things come to those who (can) wait HotNets 2008
Home is where the (fast) Internet is: Flat-rate compatible incentives for reducing peak load ACM/HomeNets 2010
How many tiers? Pricing in the Internet transit market SIGCOMM 2011
On the 95 percentile billing method Passive and Active Measurement Conference 2009.
On economic heavy hitters: Shapley value analysis of 95th percentile pricing Internet Measurement Conference 2010.
Time-Dependent Internet pricing, Internet Technologies and Applications 2011.
Good things come to those who (can) wait: or how to handle Delay Tolerant traffic and make peace on the Internet
Nikolaos Laoutaris and Pablo Rodriguez – Telefonica Research
Full paper link at citeseer http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.184.9482
This paper talks about time shifting Delay Tolerant (DT) traffic in order to reduce bills for ISPs. Two schemes are posited
User incentives – users are encouraged to delay downloading with a reward scheme
Internet Post Offices (IPOs) – storage for store-and-forward relays for DT traffic.
The authors identify a significant opportunity to reduce bills for ISPs by finding traffic which can be moved in time and hence smooth the traffic flow. The key is to provide incentives for users to move their flow from busy periods (which contributes to the 95th percentile price charged by ISPs) and to less busy periods. A second important component is to identify those flows which are delay tolerant. This must be done while keeping the flat-rate charging scheme.
The incentives are provided by a scheme which gives the users higher
than advertised bandwidth during off-peak hours – this bandwidth will
typically cost the providing ISP nothing. This scheme assumes that
the typical user will be allowed access at rate 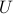 throughout the day.
A user participating in the incentive scheme will be allowed access
at rate
throughout the day.
A user participating in the incentive scheme will be allowed access
at rate 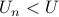 during the
during the  busy hours and
busy hours and 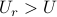 during off peak hours.
The
during off peak hours.
The  in
in 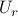 stands for reward and the
stands for reward and the 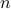 in
in 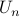 for nice.
If
for nice.
If 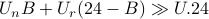 then the average rate of transfer for
the user is much higher than the non-participating user. The authors
suggest that the scheme can be modified by having several more levels
during the day.
then the average rate of transfer for
the user is much higher than the non-participating user. The authors
suggest that the scheme can be modified by having several more levels
during the day.
Internet Post Offices (IPOs) collect the DT traffic from end users in an opaque way. In once scenario a local ISP operates a local IPO. In another they are insalled and operated by CDN-like businesses which specialise in DT traffic. In scenareio one the IPOs are co-located at the ISP access providing data transfer at rates limited only by the access network. The user who wishes to send large amounts of data sends it out to the IPO immediately and it is sent on to the final destination from the IPO off-peak saving money for the ISP. The user is incentivised to do this by the scheme above. In the CDN approach the CDN operators use store and forward to transmit delay tolerant traffic in the off-peak.
Potential gains for the schemes are tested by looking at data from real traffic traces from transit ISPs.
Home is where the (fast) Internet is: Flat-rate compatible incentives for reducing peak load
Parminder Chhabra, Nikolaos Laoutaris, Pablo Rodriguez – Telefonica and R. Sundaram – Northeastern University
This paper looks at a model of reducing peak-rate load by incentivising users to move from peak rate slots to off-peak time periods. It has its roots in their HotNets 2008 paper “Good things come to those who (can) wait”. (Users are granted bandwidth in the off-peak for good behaviour in the on-peak.)
Data: The dataset is from a large transit provider. 12 million ADSL users uplink and downlink volumes over 5 minute intervals for several weeks in 2008. The provider connects to over 200 other networks. WIDE network data (Japan link) is also used. They classify the traffic by application – unfortunately the two scenarios lead to estimates of P2P traffic varying as 12–22% of all traffic throughout the day (pessimistic assumptions about classification or 74–88% throughout the day (optimistic assumptions).
Model: The model is of a user's traffic as a vector over “slots” in time. The ISP
“bids” to make users move traffic to different slots. The model also incorporates
a “peak hour” which is the set of busiest slots (defined by a link utilisation).
A threshold 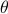 is set which is the maximum desirable
utilisation. The model is then to rearrange the users’ “elastic traffic”
while providing the extra bandwidth and keeping the peak bandwidth below
. ISPs can be “omniscient” (offering different incentives to
different users) or “oblivious” (offering the same incentive to all users).
The incentive offered to user
is set which is the maximum desirable
utilisation. The model is then to rearrange the users’ “elastic traffic”
while providing the extra bandwidth and keeping the peak bandwidth below
. ISPs can be “omniscient” (offering different incentives to
different users) or “oblivious” (offering the same incentive to all users).
The incentive offered to user 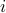 in the omniscient case is an
off peak bandwidth of
in the omniscient case is an
off peak bandwidth of 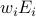 (this is the total amount of extra traffic which
can be sent in the off-peak) where
(this is the total amount of extra traffic which
can be sent in the off-peak) where
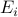 is the amount of traffic shifted away from the peak hour and
is the amount of traffic shifted away from the peak hour and 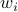 is
the increased bandwidth factor. (Note, it would seem that, if not carefully handled,
this could create an incentive for a user to make spurious downloads to
increase their capacity off-peak.) Users are split into “all-or-none” and
“fractional” users. The former shift all elastic traffic or none of it, the
latter may shift a fraction. The authors sketch a proof that the “fractional
users” and “omniscient ISP” problem is solvable in polynomial time.
is
the increased bandwidth factor. (Note, it would seem that, if not carefully handled,
this could create an incentive for a user to make spurious downloads to
increase their capacity off-peak.) Users are split into “all-or-none” and
“fractional” users. The former shift all elastic traffic or none of it, the
latter may shift a fraction. The authors sketch a proof that the “fractional
users” and “omniscient ISP” problem is solvable in polynomial time.
The incentives is modelled as an ISP “bid” (by offering a
for the user to shift their elastic
traffic. User “greediness” is modelled as resistance to move (or the
amount of increase required to make them move). This is
distributed between users, in one model using a pareto distribution
and in another as a flat distribution.
The modelling proceeds by picking a maximum utilisation for a
link and looking at the amount of traffic expansion that the ISP has
to provide in the off-peak to incentivise the users to make this move.
How many tiers? Pricing in the Internet transit market
Vytautas Valancius, Christian Lumezanu, Nick Feamster (Georgia Tech), Ramesh Johari (Stanford), Vijay Vazirani (Georgia Tech)
This paper deals with the problem of ISPs selling contracts to other (customer) ISPs. Transit ISPs implement policies which price traffic by volume or by destination with volume discount and cheaper prices to destinations which cost them less. The paper studies destination based tiered pricing with the idea that ISPs should unbundle traffic and sell pricing in tiers according to destination to maximise profits.
The background section offers a useful taxonomy of current bundles sold by transit ISPs. This arises from discussions with ISPs.
“Transit” – conventional transit pricing, sold at a blended rate for all traffic to all destinations ($Mbpsmonth). Blended rates have been decreasing at 30% each year historically. (Note – conversation with authors confirms this is usually 95th percentile).
“Paid peering” – like conventional peering but one network pays to reach the other. off-net (destinations outside its network) and on-net (destinations within its network) may be charged at different rates. E.g. national ISPs selling local connectivity at a discount.
“Backplane peering” – an ISP sells global transit through its background but discounts traffic it can offload to peers at same Internet exchange. Smaller ISPs may buy this if they cannot get settlement-free peering at exchange.
“Regional pricing” – transit providers price different geographical regions differently. Rare that more than one or two extra price levels are used for regions.
Authors show that coarse bundling can lead to reduced efficiency. Providers lose profit and customers lose service. In an example the blended rate price which maximises profit gives both less profit and lower surplus to consumers than two rates for two demand curves. An example is also given with a CDN which wants to move demand intradomain between two PoPs. The traffic is local to the PoPs and hence has lower cost to the network than typical traffic but is high in volume. If charged at the blended rate the CDN is highly incentivised to buy a direct link itself although the ISP providing transit could have carried that traffic and made profit while still charging the CDN less than paying for its own link. (Figure 2).
Section 3 of the paper creates a model of ISP profit and
customer demand. Profit is modelled as
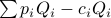 where
where 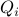 is the demand for traffic
in flow
traffic given the price vector (over all flows),
is the demand for traffic
in flow
traffic given the price vector (over all flows),
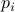 is the price of class traffic and
is the price of class traffic and 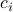 is the cost
of serving traffic in flow .
Demand is modelled in two ways: Firstly with “constant elasticity demand”
(CED) –
is the cost
of serving traffic in flow .
Demand is modelled in two ways: Firstly with “constant elasticity demand”
(CED) – 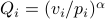 where
where 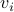 is the
valuation parameter and
is the
valuation parameter and 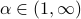 is
the price sensitivity. Secondly with “logit demand”,
is
the price sensitivity. Secondly with “logit demand”,
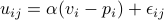 where
where
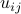 is the utility of consumer
is the utility of consumer 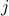 using flow
using flow
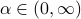 is elasticity and is
an average “maximum willingness to pay”. The
is elasticity and is
an average “maximum willingness to pay”. The
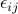 have a Gumbel distribution (standard
in the logit model).
The logit model then shares flows between customers with the
share
have a Gumbel distribution (standard
in the logit model).
The logit model then shares flows between customers with the
share 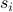 for flow (the probabiltity a given customer
will use flow ) is
for flow (the probabiltity a given customer
will use flow ) is
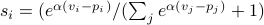 .
The plus one is to allow a “no travel” decision
.
The plus one is to allow a “no travel” decision 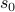 such that the
sum to one. This, again, is standard from choice theory.
such that the
sum to one. This, again, is standard from choice theory.
Profit maximising prices for logit and CED can be derived theoretically but in the logit case a heuristic descent algorithm must be used to find this optimum. Bundled prices are then tested by setting a number of pricing points and bundling flows.
ISP costs are approximated in seveal ways (as ISPs are reluctant to share this information).
Cost as a linear function of bandwidth used.
Transit cost changing with distance either as a linear cost with distance or as a concave cost with distance.
Cost as a function of destination region (assuming metropoliton, national, international, classified approximately as step functions based on distance).
Cost as function of destination type (related to on-net/off-net), approximated by making traffic to peers cost twice that of customers (traffic between customers allows the ISP to bill twice). This is approximated with a factor
for each distance which splits traffic into customer
or peer.
Bundling is done by several strategies:
Optimal (all combinations of a given number of bundles tried)
Demand weighted (tries to give bundles equal total flow demand but keep high demand flows in same bundle).
Cost weighted (Similar but with cost).
Profit weighted (Similar but with profit).
Cost division (bundles divided according to cost of flow).
Index division (as above but equal number of flows in each bundle).
Data sets:
EU ISP from 2009
flows from a CDN
Internet 2 data
The basic conclusion is that only a small number of tiers are required to get near to 100% of the possible profit. Contracts with only three or four tiers bundled on cost and demand works well. Contracts based on discounts for local traffic (standard practice) are sub optimal.
On the 95 percentile billing method
Xenofontas Dimitropoulos, Paul Hurley, Andreas Kind and Marc Ph. Stoecklin (ETH Zurich and IBM Research Zurich)
Full paper link at citeseer http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.146.5031
This paper describes the commonly used 95-percentile billing method which is often used by ISPs to bill other ISPs. The 95-percentile billing method is as follows:
Set a billing rate $y per Mbps (Megabit per second).
Take a month of traffic counts for the entity you wish to bill.
Split the traffic into equal sized time periods of length
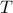 (often
5 minutes).
(often
5 minutes).Calculate the mean rate in Mbps for each time period.
Find the rate
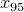 Mbps of the time period which is the 95th percentile – that
is 5% of time periods have more traffic and 95% have less traffic.
Mbps of the time period which is the 95th percentile – that
is 5% of time periods have more traffic and 95% have less traffic.The total bill for that month for that entity is
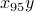 .
.Sometimes it is the case that
is calculated separately
for inbound and outbound and the maximum taken.Usually it is not the actual traffic which is measured (by packet) but an approximation reconstructed from netflow data.
The aim of the paper is to look at how choice of the time period 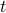 and how aggregation of billed entities affects the amount billed.
The data sets are
and how aggregation of billed entities affects the amount billed.
The data sets are
Netflow trace from web host with 46 websites (27 days in April 2008) – lowest volume websites are stripped from analysis
tcpdump trace from medium volume website on this host (30 days in July 2007)
Medium sized enterprise campus network (transit services from commercial and academic ISP) this is a tcp dump for 63 days (March 2008)
Findings about window size are:
Usually making the window size
smaller will make largerIn atypical cases this can be reversed (larger windows make
larger).However, 11 from 34 sites were atypical so typical is not very typical.
Higher mean traffic levels tend to make the dependence on
weaker.This is related to the self-similarity of web traffic. For self-similar traffic he 95th percentile should decrease polynomially as the aggregation window
increases.
Netflow data is often used for billing individual sites. Volumes and lifetimes of flows are collected and it is assumed that the volument of a flow is smoothed across its lifetime. In some cases actually looking at the traffic in terms of packets not flows can make a difference because of this approximation. In most traces there was little difference between exact packet accounting and approximate flow accounting. However, the second month of campus data showed a signficant (30%) difference. This is because this data set shows a large number of long-lived flows which ‘‘spike" periodically shifting up the 95-percentile.
The main conclusion here is that ISPs should use a standardised method to calculate 95-percentile to allow fair and easy comparison of billing across possible providers.
On economic heavy hitters: Shapley value analysis of 95th percentile pricing
Rade Stanojevic, Nikolaus Laoutaris and Pablo Rodriguez
Full paper link at SIGCOMM site (IMC paper) http://conferences.sigcomm.org/imc/2010/papers/p75.pdf.
This paper analyses the contribution of the individual users to the billing of an ISP. The basic contribution here is the Shapley value formulation. This asks the question ‘‘what contribution does a given user make to the 95th percentile value?“ The question is not so straightforward: consider a user who generates no traffic during the time period billed as 95th percentile, if that user were the only source of traffic then some billable traffic would still have been generated. A toy model is used to illustrate this. The Shapley value is a method for working out the contribution a given user should make: the ‘‘relative cost contribution”.
Consider a set 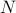 of users who contribute traffic.
Let
of users who contribute traffic.
Let 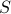 be some set of users who generate traffic.
Let
be some set of users who generate traffic.
Let 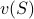 be the value which would be charged (using 95th percentile)
to the traffic generated by these users. The Shapley value of
the th user is then
be the value which would be charged (using 95th percentile)
to the traffic generated by these users. The Shapley value of
the th user is then
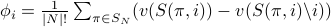 where
where 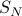 is the set of all possible permutations of (
is the set of all possible permutations of (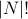 of them),
of them),
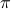 is one such permutation, and
is one such permutation, and 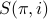 is the set of users who
arrive not later than in the permutation .
The equation can be interpreted as averaging over the contribution to the
cost which is made by the user if the following procedure were followed:
is the set of users who
arrive not later than in the permutation .
The equation can be interpreted as averaging over the contribution to the
cost which is made by the user if the following procedure were followed:
Arrange the users in random order.
Add on the traffic for each user in turn until user
is reached.Work out the additional cost that the user
imposes on the 95th
percentile.Average this cost over all possible permutations of user arrivals. It can be shown that
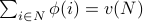 as expected.
as expected.
In fact this is extremely computationally expensive ( permutations
to examine). However, the authors use sampling of permutations to get
an answer which is a statistically unbiased and efficient estimator
for the true value.
Empirical results are gained by analysing real data sets from ISPs. One data set is of 10,000 ADSL users in a major access provider. They use this to calculate the error introduced by sampling the Shapley value. Following this they use this framework to split the day into 24 hours and work out how much the contribution from each hour is using the same framework (disaggregating by hour not by user). Their work shows that, for their dataset, a peak period from 9am to 4pm contributes almost all of the cost in terms of Shapley value.
An expanded version of the paper is available as a technical report at http://www.hamilton.ie/person/rade/TREHH.pdf. This includes extra graphs and proofs of the unbiased nature of the statistical estimator for Shapley value and that the estimator for individual users sums to the estimator for that group of users.
Time-Dependent Internet Pricing
Carlee Joe-Wong, Sangtai Ha and Mung Chiang (Princeton)
Full paper link at ITA site http://ita.ucsd.edu/workshop/11/files/paper/paper_2186.pdf.
This paper looks at time-dependent pricing schemes. A day is split into 48 half hour periods indexed by an integer. The system is known as TUBE (Time-dependent Usage-based Broadband-price Engineering). They use a control loop to adapt the prices ISPs charge users in response to changing behaviour.
A “waiting function” describes
a users willingness to wait an amount of time
given reward 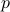 . The problem is first set as a convex
optimisation problem given the target for the ISP
which is to minimise the cost paid for links plus
the cost paid in “rewards” to users. The cost
function for links is assumed to be piecewise linear
with bounded slope. Essentially the modelling occurs
as if all ISP traffic went through a single link
and a price were paid on this in every period
. The problem is first set as a convex
optimisation problem given the target for the ISP
which is to minimise the cost paid for links plus
the cost paid in “rewards” to users. The cost
function for links is assumed to be piecewise linear
with bounded slope. Essentially the modelling occurs
as if all ISP traffic went through a single link
and a price were paid on this in every period
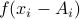 where
where 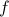 is the cost function,
is the cost function,
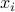 is the usage in period and
is the usage in period and 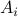 is
the available capacity in period .
is
the available capacity in period .
Following this, a dynamic version of the model is
developed in online and offline settings. The
offline version assumes Poisson arrivals within
a time period with a rate
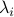 and
exponentially distributed file sizes (the
latter assumption is questionable as most studies
show larger than exponential tails in file
size distributions). The offline version chooses
the rewards to maximise ISP profit. It is shown
that this is equivalent to the static model but
with “leftover” downloads which do not complete
in one period added on to the start of the next.
An online version is developed which solves
the optimisation as a dynamic programming problem
and calculates the optimal reward for steps ahead
based on the current situation, existing rewards
for
and
exponentially distributed file sizes (the
latter assumption is questionable as most studies
show larger than exponential tails in file
size distributions). The offline version chooses
the rewards to maximise ISP profit. It is shown
that this is equivalent to the static model but
with “leftover” downloads which do not complete
in one period added on to the start of the next.
An online version is developed which solves
the optimisation as a dynamic programming problem
and calculates the optimal reward for steps ahead
based on the current situation, existing rewards
for  steps ahead and predictions about arrivals
based on past behaviour. The assumption remains that
the system is constrained by a single bottleneck link.
steps ahead and predictions about arrivals
based on past behaviour. The assumption remains that
the system is constrained by a single bottleneck link.
The authors then describe a method which calculates the “waiting function” (a measure of the willingness of users to defer their downloads for given rewards). This is done by estimating the difference in demand between time independent and time dependent pricing. This is done by estimating a (potentially very large) number of parameters for each application type.
Simulation is performed using an input which is aggregate traffic from a large ISP. The authors show that the reward system can be used to smooth traffic throughout the day and hence to increase ISP profit.
More details and an expanded paper is C. Wong, S. Ha and M. Chiang, Time-Dependent Broadband Pricing: Feasibility and Benefits, ICDCS 2011. http://www.princeton.edu/~chiangm/timedependentpricing.pdf. This also contains a list of time dependent pricing papers in various fields.
Home. For corrections or queries contact: Richard G. Clegg (richard@richardclegg.org)