Networking Papers – Miscellaneous
This section contains papers about networks not fitting into any of my other categories for papers about networks.
The power of prediction: Cloud bandwidth and cost reduction SIGCOMM 2011
Towards predictable datacenter networks SIGCOMM 2011
The power of prediction – Cloud bandwidth and cost reduction
Eyal Zohar, Israel Cidon, Israel Institute of Technology, Osnat Mokryn, Tel Aviv Academic College
This paper deals with reducing costs for cloud computing users. Cloud customers use “Traffic Redundancy Elimination” (TRE) to reduce bandwidth costs. Redundant data chunks are detected and removed – cloud providers will not implement middleboxes for this as they have no incentive. The paper gives a TRE solution which does not require a server to maintain client status. The system is known as PACK “Predictive ACKnowledgements” which is receiver driven.
The basic unit of data is the chunk. The receiver implements a chunk store which operates by the LRU principle. Chunks are identified by “hints” which are easily computed functions which identify data with a fast algorithm with low false positives. If hints match then SHA-1 signatures are checked and if matched then data about subsequent chunks (referred to as a “chain”) can be retrieved from pointers in chunk data. So, a chunk is the data, a signature to uniquely identify the data and a link to the next chunk (if received). On receiving a match the receiver asks the sender if the next chunks will be the same as the ones in its store by sending the identity of several chunks. This is known as a PRED command (predict). If this is correct the sender sends PRED-ACK and the receiver sends the chunks to its own TCP input buffers. If the prediction is not correct the sender continues to send as normal. The TCP Options field is used to carry the PACK wired protocol.
Section 4 lists some optimisations.
If lots of correct predictions are made then the rate at which the receiver sends predictions could be a bottleneck. An optimistic algorithm sends more predictions if many predictions are successful.
Several chunks can be combined to a similar effect.
If changes in data are scattered then PACK becomes inefficient. A hybrid mode allows searching for dispersed changes and moving to a sender driven mode.
Evaluation is tried on 24 hours of data from an ISP PoP. Youtube data isolated using DPI (13% by volume). PACK is tested for ability to reduce redundant data and reduces traffic by 30% (after an initial period where the cache of chunks is filling). Static data sets of the linux kernel in various versions (40 versions) and a user Gmail account with 1140 messages (1.09GB) were checked. Together the set of linux kernel files showed 83.1% redundancy and the email 31.6%. The algorithm is further analysed for computational load in the server and receiver based modes. The computational load to some extent reduces the benefits of the traffic reduction (in a situation where users pay for both traffic and CPU use) but still results in a reduction of bill by 20% (for the Youtube traffic example).
Tests are run on a fully working and implemented system with a workload consisting of emails, FTP data, http videos. CPU usage and real and virtual traffic volumes were checked. The cost estimates were based on amazon EC2 pricing comparing PACK with a sender based Redudancy Elimination algorithm similar to one from literature. The rival does not perform well as the SHA-1 matching on every chunk produces CPU usage expense.
Towards predictable datacenter networks
Hitesh Ballani, Microsoft Networks, Paolo Costa, Imperial College, Thomas Karagiannis, Ant Rowstron, Microsoft Networks
This paper looks at the issue of reducing variability in performance in data centre networks. Variable network performance can lead to unreliable application performance in networked applications – this can be a particular problem for cloud apps. Virtual networks are proposed as a solution to isolate the “tenant” performance from the physical network infrastructure. The system presented is known as Oktopus. The system provides a tradeoff between guarantees to tenants, costs to tenants and profits to providers by mapping a virtual network to the physical network.
In the introduction a useful study of the intra-cloud network bandwidth is done by looking at results from past studies (figure 1). Large differences (factor of five or more in some studies) are observed.
Tenant requests are abstracted to simply a number 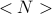 of virtual
machines (assumed standard in terms of CPU memory and storage) and a
bandwidth
of virtual
machines (assumed standard in terms of CPU memory and storage) and a
bandwidth 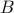 , making a virtual switch with a total bandwidth
, making a virtual switch with a total bandwidth 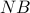 but
with a limit on each VM of . In this case the subscription request
is
but
with a limit on each VM of . In this case the subscription request
is 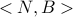 . This is known as a “Virtual cluster”.
. This is known as a “Virtual cluster”.
Some networks are oversubscribed – in these cases a
request is described as 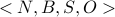 where
where 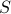 is the size of groups in
which the
is the size of groups in
which the 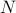 machines are clustered (
machines are clustered (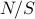 groups) and
groups) and 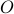 is
an oversubscription factor. VMs in group are connected by a virtual
group switch of capacity and groups are interconnected by a link
of capacity
is
an oversubscription factor. VMs in group are connected by a virtual
group switch of capacity and groups are interconnected by a link
of capacity 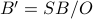 . This is known as a “Virtual oversubscribed
cluster”.
. This is known as a “Virtual oversubscribed
cluster”.
Other topologies could be offered – for example a clique (which would have high max bandwidth but limit provider flexibility).
The Oktopus system (named after Paul the psychic octopus – hence German spelling) implements these virtual abstractions. Requesting tenants can ask for a virtual cluster or a virtual oversubscribed cluster for connections. A management plance (logically centralised) performs admission control and maps requests to physical machines. A data plane uses rate-limiting at end-hosts to enforce bandwidth limits.
The algorithm which maps requests onto physical networks focuses on tree-like
physical topologies. Allocating virtual oversubscribed clusters is
allocating virtual clusters of size 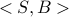 with links of size
with links of size 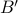 between
them.
between
them.
Tenants without virtual networks should be guaranteed a fair share of network bandwidth. Tenants on virtual networks are given high priority traffic with guaranteed but limited bandwidth. Other traffic gets fair share of residual bandwidth. Limiting the share of total bandwidth used by virtual networks guarantees a minimum QoS for non virtual network clients.
In non-tree networks then routing may be an issue. Load balancing is used to spread traffic across paths.
Evaluation is by simulation on a testbed consisting of 25 physical machines. A three-level tree topology is used and no path diversity. The simulation is of a datacentre with 16,000 physical machines and 4VMs each machine. The machines are arranges in 40 machines racks with a top of rack switch. These connect to aggregation switches which connect to a datacentre core switch.
The allocation algorithm for VMs is greedy (since the full problem
is NP hard).
If 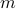 out of VMs are places on a single physical machine
then
out of VMs are places on a single physical machine
then 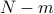 must be on other phyical machines and
must be on other phyical machines and 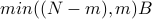 bandwidth must be available.
Assume
bandwidth must be available.
Assume 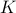 slots for VMs per machine. Each
link capacity
slots for VMs per machine. Each
link capacity 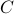 .
. 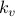 is number of empty slots on
is number of empty slots on  .
. 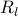 is residual bw for link
is residual bw for link 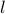 . The number of VMs for request for
that
can be allocated on machine with outbound link is:
. The number of VMs for request for
that
can be allocated on machine with outbound link is:
![M_v = { m in [0,min (k_v,N)] s.t. min(m,N-m)*B leq R_l}](eqs/1362857714096164477-130.png) .
.
Simulations are run with tenant jobs modelled as independent tasks
with flows between tasks on individual VMs of uniform length 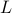 .
A simulated workflow makes some simple assumptions about length
of task completion. The network is assumed to have more demand
for bandwidth than it can handle. A baseline comparison is tenants asking only
for a number of machines which are greedily allocated as close
as possible. This is extended as
and to see the effects on completion times.
Completion times are much reduced by placement using oversubscription
policies as bandwidth is used more efficiently. In addition the
efficiency would allow providers to operate clouds closer to 100%
utilisation (Amazon apparently at 70 - 80%).
.
A simulated workflow makes some simple assumptions about length
of task completion. The network is assumed to have more demand
for bandwidth than it can handle. A baseline comparison is tenants asking only
for a number of machines which are greedily allocated as close
as possible. This is extended as
and to see the effects on completion times.
Completion times are much reduced by placement using oversubscription
policies as bandwidth is used more efficiently. In addition the
efficiency would allow providers to operate clouds closer to 100%
utilisation (Amazon apparently at 70 - 80%).
Home. For corrections or queries contact: Richard G. Clegg (richard@richardclegg.org)